Databricks - TAGs - Tagueando seu ambiente
- Reginaldo Silva
- 20 de nov. de 2023
- 3 min de leitura

Fala dataholics, hoje vamos falar de um recurso que existe em quase todas as ferramentas e que são muito uteis para o nosso dia a dia, o uso de TAGs, que geralmente são compostas por chave-valor, no post de hoje vamos ver como usar as tags no Databricks.
Hoje quase todas as ferramentas possuem recurso de TAG, exemplo nas Clouds (Azure, AWS e GCP) é muito comum usar TAGs nos seus recursos, seja para organização ou para mapeamento de cobrança por área de negócio.
O que veremos nesse post:
TAGs no Databricks
Objetos que podemos aplicar TAGs
Aplicando TAGs usando a interface gráfica
Aplicando TAGs usando SQL
Permissão para adicionar TAGs
Usando Tags no Advanced Search
Monitorando TAGs com tabelas de sistemas
Limitações

Dentro do Databricks o recurso de TAGs já erá disponível, você já era capaz de taguear seus clusters, jobs e mais alguns objetos, contudo, esse recurso está evoluindo e melhorando cada vez mais, então se você quer manter seu ambiente organizado, usar TAGs é um dos caminhos.
Agora você pode taguear não somente Clusters e Jobs no Workflow como pode aplicar Tags em: catálogos, schemas\databases, tabelas, colunas, modelos, queries, dashboards e warehouse.
A novidade aqui talvez seja mais para os objetos como catalogo, schema, tabela e colunas, veremos como adicionar TAGs nesses recursos pelo visual e via SQL e depois como consultar essas TAGs.
Visualmente é muito simples adicionar novas TAGs, em todos os objetos você notará um novo botão de add Tags.


Você notará que essas TAGs são armazenadas e você pode reutilizá-las para todos os outros objetos, exemplo, após criado a TAG ela irá aparecer numa lista e você pode selecionar, evitando erros de digitação.

Você pode repetir esse passo até no nível de colunas.

Exemplo, você pode taguear colunas com dados sensíveis ou com informações importantes facilitando a governança de dados.
Também podemos aplicar TAGs através da linguagem mais querida do mundo, usando SQL pode facilitar para adicionar TAGs em escala para diversos objetos.
No exemplo abaixo estamos usando um ALTER TABLE, contudo, isso funciona para todos os recursos aplicando a opção de SET ou UNSET TAGs.
alter table dev.db_demo.tbOrdersLiquid SET TAGS ('project' = 'datainaction', 'type' = 'table')
A permissão mínima para que usuários possam adicionar TAGs é: APPLY TAG.

Após Tagueado todo seu ambiente, utilizaremos essas TAGs a nosso favor, na tela de busca avançada no Databricks temos a opção de filtrar por TAGs, isso ajuda demais no dia a dia.
Para abrir a tela de busca avançada no Databricks, basta clicar sobre o campo de buscas e depois clicar em 'Open Advanced Search'.

A tela abaixo será aberta, aqui podemos procurar qualquer coisa no nosso ambiente, se você quiser encontrar um notebook, basta digitar um trecho dele nessa tela e ele será encontrado, é uma feature sensacional, uso muito no meu dia a dia esse recurso de busca avançada.

Se você estiver buscando por tabelas, quando selecionar a opção TAG note que ele já expande a lista de TAGs para busca, então você pode aplicar busca de tabelas que possuem determinadas TAGs, se o seu ambiente for padronizado isso pode te ajudar.

Temos novas tabelas de sistema para utilizamos a nosso favor, são elas:
INFORMATION_SCHEMA.CATALOG_TAGS - Tags no nível de catálogo
INFORMATION_SCHEMA.COLUMN_TAGS - Tags no nível de colunas
INFORMATION_SCHEMA.TABLE_TAGS - Tags no nível de tabela
INFORMATION_SCHEMA.SCHEMA_TAGS - Tags no nível de schema
Detalhe que podemos pesquisar por elas num catálogo especifico ou no catálogo SYSTEM que traz informações de todos os catálogos.
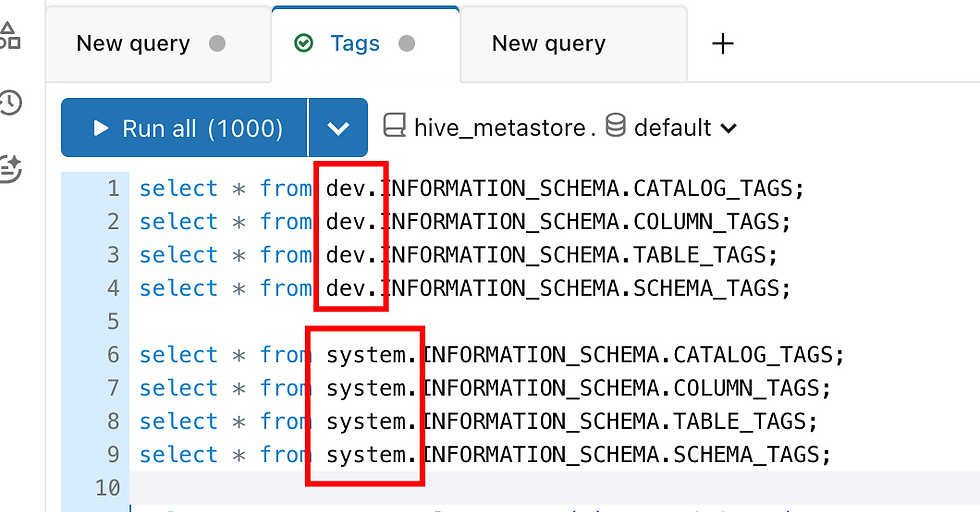
Logo, podemos fazer uma busca para agrupar todas as nossas TAGs:

Quantidade de objetos tagueados.
select tag_name, count(*) as qtd from (
select tag_name,tag_value from system.INFORMATION_SCHEMA.CATALOG_TAGS union all
select tag_name,tag_value from system.INFORMATION_SCHEMA.COLUMN_TAGS union all
select tag_name,tag_value from system.INFORMATION_SCHEMA.TABLE_TAGS union all
select tag_name,tag_value from system.INFORMATION_SCHEMA.SCHEMA_TAGS
)tags
group by all
Nem tudo na vida são flores, como notou, ainda não temos todas as TAGs rastreadas nas tabelas de sistema, exemplos TAGs ao nível de JOB e Cluster precisaríamos retornar via API.
Outro ponto, como pode notar nos jobs abaixo, as tags não têm o padrão de chave-valor, ficando mais difícil para buscas e agrupamento, para recuperar elas precisaria ser via API ou usando o SDK.

Apesar dessas limitações, não deixe de padronizar seu ambiente com TAGs, é um recurso extremamente útil e agregador.
E aí o que achou?
Fique bem e até a próxima.
Referências:


Comentários