Delta Lake - ReplaceWhere vs Merge - Reduzindo horas para minutos
- Reginaldo Silva
- 19 de fev. de 2024
- 6 min de leitura

Atualizado: 19 de fev. de 2024
Fala dataholics, vamos sair um pouco do tema de Azure Function essa semana, e o post de hoje será sobre melhoria de performance nas nossas escritas em tabelas Delta, você já viu a diferença entre ReplaceWhere e Merge?
Para o post de hoje entenderemos alguns pontos importantes sobre performance na escrita de dados, coisa bem corriqueira em nosso dia a dia, criaremos um caso de uso e ver exemplos do que pode dar errado em caso de uso incorreto.

O que veremos no post de hoje:
Escrevendo com comando MERGE
Escrevendo com Replace Where
Diferença de perfomance
Cuidados com ReplaceWhere
Resumo
Escrevendo com comando MERGE
A utilização do comando MERGE é muito comum em nosso mundo, quase impossível você não ter visto esse comando trabalhando com dados. Para manipulação simples de tabelas é mais comum usarmos os comandos INSERT, UPDATE e DELETE, embora no mundo de Analytics temos necessidades um pouco diferente, exemplo o famoso Upsert.
O que é Upsert? Basicamente é quando você precisa inserir um novo registros, mas com uma condição, se ele já existir, ao invés de inserir é executado uma atualização da versão existente, seria como fazer algo assim:
IF exists(registro):
Update
else:
InsertMas usando apenas um comando:
MERGE INTO dev.bronze.pedidos as t
USING vw_updates as s
ON s.order_id = t.order_id
WHEN MATCHED
THEN UPDATE SET *
WHEN NOT MATCHED
THEN INSERT * O comando MERGE possui essas validações:
WHEN MATCHED: Quando o registro existir: faça isso (Update)
WHEN NOT MATCHED [BY TARGET]: Quando não existir no destino: faça isso (Insert)
WHEN NOT MATCHED BY SOURCE: Quando não existir na origem: faça isso (Delete)
A terceira validação é bem incomum de ser utilizada, pois, você precisaria comparar praticamente as duas bases inteiras, embora, combinado com algumas técnicas pode ser utilizado, ele foi adicionado recentemente.
Além de servir para fazer UPSERT o MERGE é a maneira que usamos para aplicar transações de CDC nas nossas tabelas, dá uma conferida nesse post:
Exemplo de utilização do MERGE aplicando CDC:
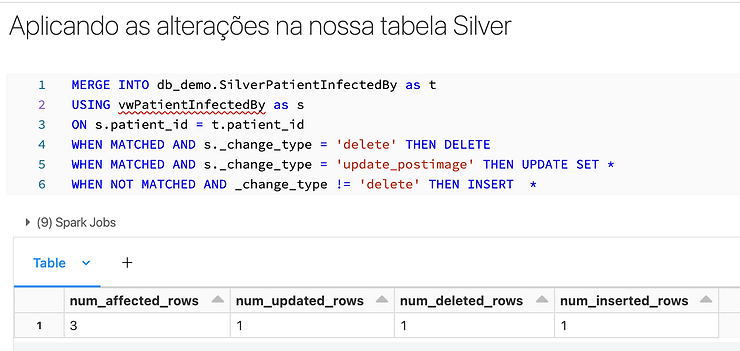
O comando MERGE é muito útil, mas traz consigo um problema, mas esse problema não só dele, basicamente ele precisa fazer um JOIN entre a tabela de entrada (que seriam os dados que você quer carregar para a tabela final) e a sua tabela final, esse JOIN é feito pela chave única da sua tabela, o problema aqui é o mesmo de sempre, JOINs são custosos.
Existem algumas técnicas que você pode utilizar para melhorar a performance dos seus JOINs ou comandos MERGE, a primeira é garantir que a chave utilizada no JOIN esteja no seu Liquid Cluster ou Zorder, isso é imprescindível para uma boa performance, outra maneira seria utilizar filtros seletivos em ambos os lados e minimizar a quantidade de dados que precisa ser lida, embora, esse depende muito mais da regra de negócio e modelagem das tabelas.
Vamos ver um cenário simples de MERGE, no meu exemplo tenho uma tabela simples de pedidos com 59 milhões de registros, relativamente pequena, em casos reais é muito comum fazermos JOINs com tabelas de bilhões de registros.

Abaixo é a distribuição de dados na minha tabela, nesse exemplo vamos ver um caso simples, usarei o mês 10 de 2023 de exemplo, digamos que nesse mês temos muitos registros com informação desatualizada em relação à origem, então carregarei o mês 10 novamente e faremos um MERGE para aplicar o UPSERT em todos os registros desse mês.

Aqui estamos criando uma VIEW chamada 'vw_updates' com todos os registros do mês 10 que estão vindo da Origem e usaremos essa View para aplicar o MERGE, note que ela tem o mesmo numero de registros da tabela sendo 1.590.054 registros, então na teoria teremos Update de todos registros.

Rodando nosso comando de MERGE abaixo temos o tempo total de 3 minutos para executar o comando, na teoria é um tempo pequeno, no resultado podemos notar que o número de linhas afetadas e numero de linhas atualizadas são iguais o que confirma que só tivemos Update.

Bom, Reginaldo, é assim que sempre fiz e faço até hoje, tem outra opção?!.
Escrevendo com ReplaceWhere
Sim, temos uma opção chamada de ReplaceWhere!
Observação: Podemos usar tanto com SQL ou PySpark!

Basicamente a lógica do ReplaceWhere é: Deleta tudo e insere de novo
Ele sempre vem acompanhado de uma cláusula que você precisa informar, como se fosse um WHERE, ele apagará todos os dados que atenderem essa cláusula e irá inserir tudo que você esta trazendo novamente.
Isso, na prática, é extremamente mais performático que usar um comando MERGE, embora, a utilização do ReplaceWhere é para cenários bem mais específicos, enquanto o comando MERGE atende praticamente todos os cenários de escrita de dados.
Vamos pensar no nosso caso que vimos acima com o MERGE: Preciso atualizar todo o mês 10 de 2023, logo carregarei todo ele para uma área de Stage\Landing\Transient, se eu já tenho ele todo carregado ali, então ao invés de fazer um MERGE é muito mais simples substituir o que esta na minha tabela (que estava errado ou faltando Updates) por esses dados.
Vamos ver na prática:
Nesse caso, ao invés de criar a VIEW jogamos todos os dados para em um Dataframe.

Executando nosso comando com ReplaceWhere note que saímos de um tempo de 3 minutos para 28 segundos.

Sérião mesmo, isso é muito foda!
Ah Reginaldo, são apenas 3 minutinhos, isso não vale nada!
Já consegui ganhos de redução de cargas de 8 horas para 30 minutos em casos de tabelas maiores apenas reescrevendo a lógica de MERGE para ReplaceWhere (foi necessário um bom estudo para essa troca) quando você começa trabalhar com tabelas acima de bilhão as coisas começam a ficar sérias e performance deixa de ser uma opção.
E se o seu pipeline faz o mesmo para 10 tabelas, já estamos falando de redução de 30 minutos para uns 5 minutos, quando você aplica em escala os valores vão fazendo muito mais sentido.
Restrição para inserção fora do Range:
Para evitar que você cometa um erro grave de apagar dados de um range e inserir de outro é feito uma validação e gerado um erro caso você faça isso, exemplo, carregando dados do mês 10 no mês 09.

Você pode desabilitar essa validação, não é recomendado, embora, possam existir casos onde você queira realmente fazer isso.
spark.conf.set("spark.databricks.delta.replaceWhere.constraintCheck.enabled", False)Onde não usar o ReplaceWhere:
Para muitos cenários faz, sim, bastante sentido usar o ReplaceWhere ao invés do MERGE, até mesmo a Databricks faz essa sugestão.

Vejamos um cenário simples, tenho minha tabela de Livros na origem e quero levar ela incrementalmente para o Lake na tabela Livros_destino que esta vazia.

Vamos supor que vou usar aquela lógica clássica, fazer uma carga FULL depois levar incremental com D-7 (Os últimos 7 dias) usando um campo de data de atualização.

Então quando eu executar o ReplaceWhere abaixo, ele excluirá tudo que tem D-7 na nossa tabela destino e irá inserir essas 3 linhas acima, até aqui tudo normal, nada de novo.

Agora o que acontece se por algum motivo eu for la na tabela origem e dar um Update no campo de data de atualização para um valor fora do range? (Acredite isso pode acontecer)

Note que agora só temos duas linhas no Dataframe com dados D-7, pois, o Livro_id 8 ficou fora do Range, e lembre-se, ele já havia sido carregado na carga FULL.

Sim, teremos a perda de dados.

Basicamente, como na tabela destino o Livro_id 8 estava no Range, foi excluído, mas ele não veio no conjunto de dado dados D-7, pois, sua data não estava no range, sendo assim, não foi inserido novamente.
Ah Reginaldo, isso é regra de negócio, poderia acontecer em cargas normais também, embora, o dado não seria apagado, ficaria apenas desatualizado em relação à origem.
Vejamos outro caso, agora vai ser o contrário, vou dar um Update em um registro antigo e ele entrara no Range D-7.
Vamos pegar o registro 1 com data_atualização em 2024-01-01 e colocar para 2024-02-14, assim ele entrara no range de D-7.

Agora voltamos a ter 3 linhas no Dataframe de D-7.

Uai, meu registro do Livro 1 duplicou?

Aqui aconteceu o reverso, o Livro_id 1 já existia na tabela destino com data atualização 2024-01-01 e quando na origem sofreu update para data 2024-02-14, ele entrou no range D-7, embora o ReplaceWhere só sobrescreveu aquele Range, mantendo as duas versões.
Vale reforçar que a lógica do ReplaceWhere é diferente do MERGE, não temos Upsert aqui, então você precisa garantir na regra de negócio que eventos como esse não possam acontecer ou você terá dados inconsistentes.
Escolha um campo de data consistente que não possa sofrer alterações constantes, mas valide sempre a lógica de negócio, ficou claro que apesar de ser mais performático ele não serve para todos os cenários.
Resumo
Vimos que o comando MERGE é extremamente versátil, mas tem seus problemas de performance, por outro lado, temos o ReplaceWhere que pode ser utilizado em alguns casos melhorando consideravelmente a performance dos seus pipelines, embora traz algumas complexidades e perigos.
Estude ambos os casos e faça bom uso.
Fique bem e até a próxima.



Comentários